arXivから興味のある論文をSlackに定期通知する
概要
最近、研究室に配属されVision Language Modelを用いた研究を始めました。
ここで、やはりこの分野はホットなので毎週新しいペーパーが出てきます。これを自分で探して中身を1つ1つ確認するのは面倒なので、このフローを自動でやってくれる仕組みを作ってみました。
ちなみに、長期インターン先の社長も同じような仕組みを以前作っていたようです。実装する上で大いに参考にさせていただきました。

構成
いつもの如くAWSを用いた構成で実装を行いました。
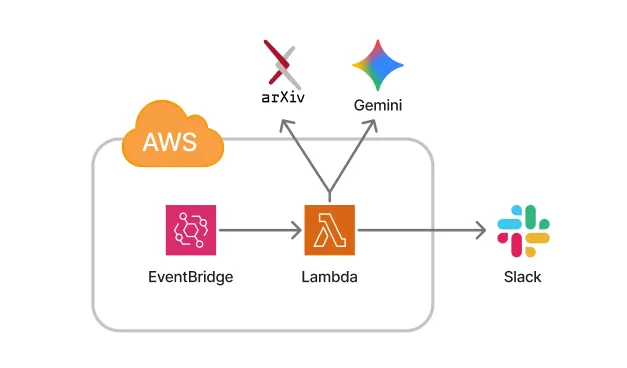
比較対象としては、Google CloudとCloudflareのサービスがあります。個人的には、Cloudflareを使いたいなあ思っていたのですが、ちょっといろんな制約があったので、割と自由でかつ慣れているLambdaのTriggerにEventBridgeを用いる構成にしました。
この前参加したCloudflare TechTalks in Kyotoのrokuoくんの登壇資料を参考にさせてもらいました。

実装詳細
今回は、定期的にarXivのAPIを使ってクエリするだけでなく、Gemini APIを用いてサマリを生成してもらうので、やりやすいかなと思い、Pythonで実装を行いました。
1. arXiv APIを用いて論文を取得
思ったよりも簡単に実装できます。
arXivからトークンを取得する必要もなく、arXivのライブラリをインストールして、クエリを投げるだけです。resultsには、arxiv.Resultのリストが入ってきます。
今回は、研究室内で任意のクエリで使いまわせるように、env.ARXIV_QUERYとenv.ARXIV_MAX_RESULTSを環境変数として設定しておきます。
(lambdaのhandlerの引数として与えるようにした方がよかったかなぁ。。。EventBridgeって引数とかも設定できるんですかね??)
import arXiv
client = arxiv.Client()
search = arxiv.Search( query=env.ARXIV_QUERY, max_results=env.ARXIV_MAX_RESULTS * 3, sort_by=arxiv.SortCriterion.SubmittedDate, sort_order=arxiv.SortOrder.Descending,)
results = client.results(search)2. GeminiAPIを用いてサマリを生成する
先ほど取得したarxiv.Resultのリストを1つ1つ処理していきます。(バッチでやればよかったなぁ。。。)
genaiはchat completion APIを持っていないのですが、openaiのAPIを使うことで、chat completion APIを呼び出すことができます。
システマチックに処理できる情報については、LLMに任せず、生成された文章に基本情報を付与しました。
def get_summary(result: arxiv.Result) -> str: text = f"title: {result.title}\nbody: {result.summary}" system_prompt = Template(SYSTEM_PROMPT).render(article_text=text) prompt = [ Message(role="system", content=system_prompt), Message(role="user", content=text), ] response = llm_client.chat.completions.create( model="gemini-2.5-flash", n=1, messages=[message.cast_to_openai_schema() for message in prompt], )
summary = response.choices[0].message.content title_en = result.title title, *body = summary.split("\n") body = "\n".join(body) date_str = result.published.strftime("%Y-%m-%d %H:%M:%S") message = f"発行日: {date_str}\n{result.entry_id}\n{title_en}\n{title}\n{body}\n"
return messageプロンプトは、参考にさせていただいた記事のものをそのまま起用しました。当時のモデルよりも賢いモデルになったので、要約に文字制限を入れてしまうと極端に情報量が少ないサマリを出してくるので、 文字数制限の指示は消しておきました。
SYSTEM_PROMPT = """### 指示 ###論文の内容を理解した上で,重要なポイントを箇条書きで3点書いてください。
### 箇条書きの制約 ###- 最大3個- 日本語
### 対象とする論文の内容 ###{{article_text}}
### 出力形式 ###タイトル(和名)
- 箇条書き1- 箇条書き2- 箇条書き3"""3. Slackに通知を行う
SlackにBotを追加するフローについては、記事が溢れているのでそちらを参考にしてください。適切な権限を与えたトークンを取得して、ワークスペースにインストールすれば 以下のコードでメッセージを送信することができるようになります。
slack_client = WebClient(token=env.SLACK_TOKEN)
for i, result in enumerate(result_list, start=1): try: message = f"{env.ARXIV_QUERY}: {i}本目\n" + get_summary(result)
response = slack_client.chat_postMessage( channel=env.SLACK_CHANNEL, text=message ) logger.info(f"Message posted: {response['ts']}")
except SlackApiError as e: logger.error(f"Error posting message: {e}")ここまでできたら、実際に実行してみると、環境変数で設定したクエリで検索された論文のサマリと一緒に指定したSlackのチャンネルへの通知が行えました!!

4. Triggerの設定を行う
Lambdaのデプロイ方法は割愛します。ECRを用いたDocker Imageでのデプロイを採用しました。uvを用いたビルドも公式からDockerfileが公開されており、ほとんどそのままデプロイできました。
トリガーの設定も簡単で、Lambda > 関数 > {関数名} > 設定 > トリガー から任意のトリガーを設定することができます。 ここで、cronの設定を行うことで、定期的にLambdaを実行することができます。 今回は、毎週月曜日の朝10時に実行するようにしました。
まとめ
執筆中に気づいてしまった設計・実装ミスが所々漏れてしまいました。。
ただ、これでかなりリサーチが楽になったので有効活用しつつ、研究室内の他の人にも使ってもらいたいです。